# General purpose R libraries
library(readr)
library(dplyr)
library(tidyr)
library(forcats)
library(gridExtra)
library(countrycode)
# Tables
library(kableExtra)
library(reactablefmtr)
# Graphs
library(ggplot2)
library(ggtext) # Add support for HTML/CSS on ggplot
library(showtext)
library(sysfonts) # System / Google fonts
library(glue)
library(ggflags)
# Other R packages
library(fontawesome)
#library(htmltools) # for building div/links
# Other settings
options(digits=4) # print only 4 decimals
options(warn = -1)
## Load fonts
# font_families_google() ## see list with available Google fonts
font_add_google(name = "Lilita One", family = "title", db_cache = F)
font_add_google(name = "Ysabeau Office", family = "subtitle", db_cache = F)
font_add_google(name = "Spline Sans", family = "text", db_cache = F)
showtext_auto()
showtext::showtext_opts(dpi = 300)
library(highcharter)Introduction
Kaggle is one of the most well-known communities of data analysts/scientists with over 10 million active users (Heads or Tails, 2020). Besides that, Kaggle offers an abundance of functionalities (Notebooks), information (through Discussions between users) and Competitions. It is worth noting that there are other similar communities but they cannot compare to the full functionality of Kaggle. For example, DrivenData could be considered an alternative for participating in ML competitions, but it neither provides the possibility to create notebooks nor has a large number of users.
![]()
Kaggle Machine Learning & Data Science Survey is an annual survey conducted by Kaggle. The platform asks its users to analyze users’ data in the context of a competition. In this notebook, I conduct an analysis based on 2021’s survey in order to compare Greek data analysts with the rest of the world.
Prerequisites
Import libraries
This notebook will definitely make some charts, so the ggplot2 package is necessary. Also, having variables with too many values (e.g. country of each Kaggle user) is an indication of using tables, and for this the reactablefmtr package will help to get a nice result.
Import data
Using read.csv() from readr package, I import my dataset and I name it as kaggle_2021. The dataset includes in the first line the question which is not required for my data analysis, so I exclude it from my dataset.
Prepare Data
Since my analysis is based on Greek users, I split the dataset into two parts. One part includes exclusively Greek users and all the rest another. Thus, we can observe any differences or similarities with broader Kaggle’s userbase.
# Recoding Q2 variable
kaggle_2021$Q2 = kaggle_2021$Q2 %>%
fct_recode(
"Other" = "Nonbinary",
"Other" = "Prefer not to say",
"Other" = "Prefer to self-describe"
)
## Recoding kaggle_2021$Q3
kaggle_2021$Q3 <- kaggle_2021$Q3 %>%
fct_recode(
"Hong Kong" = "Hong Kong (S.A.R.)",
"Other" = "I do not wish to disclose my location",
"Iran" = "Iran, Islamic Republic of...",
"UAE" = "United Arab Emirates",
"UK" = "United Kingdom of Great Britain and Northern Ireland",
"USA" = "United States of America",
"Vietnam" = "Viet Nam"
)
## Recoding kaggle_2021$Q6
kaggle_2021$Q6 <- kaggle_2021$Q6 %>%
fct_recode(
"0 years" = "I have never written code"
)
## Recoding kaggle_2021$Q4
kaggle_2021$Q4 <- kaggle_2021$Q4 %>%
fct_recode(
"Bachelor" = "Bachelor’s degree",
"PhD" = "Doctoral degree",
"Other" = "I prefer not to answer",
"Master" = "Master’s degree",
"No" = "No formal education past high school",
"ProfDoc" = "Professional doctorate",
"UniNoDegree" = "Some college/university study without earning a bachelor’s degree"
)
kaggle_2021$Q4 <- kaggle_2021$Q4 %>%
fct_relevel(
"No", "UniNoDegree", "Bachelor", "Master", "PhD", "ProfDoc",
"Other"
)
kaggle_2021_compare = kaggle_2021 %>%
mutate(Q3 = if_else(Q3 != "Greece", "Other", Q3))Kaggle’s community
One of the first thing I observed when I signed up on Kaggle was the vast majority of nationalities and the multicultural origin of the platform. Many people from many countries all in one platform gathered sharing the same passion for Data Science and Data Analytics. Something like Facebook but for Statistics :)
Nevermind, I decided to make a reactable to see from which nationalities the platform is comprised from. One out of four users are from India which makes them the most populous nation in platform. By the way, Greek users are way less making a 0.39% of Kaggle’s userbase.
NoteAssumptions Note
We should note that the results are from Kaggle’s Survey. That is to say from people that participated. An assumption has to be done that the distribution of the users that participated is the same with the ones who didn’t.
a = kaggle_2021 %>%
group_by(Q3) %>%
summarise(n = n()) %>%
mutate(pct = round(n/nrow(kaggle_2021) * 100, digits = 2)) %>%
arrange(desc(pct)) %>%
reactable(.,
defaultPageSize = 6,
theme = espn(),
columns = list(
Q3 = colDef(name = "Country"),
n = colDef(name = "Population",
defaultSortOrder = "desc"),
pct = colDef(name = "Percentage (%)")),
defaultColDef = colDef(
cell = data_bars(data = .,
text_position = "outside-base",
fill_opacity = 0.5, round_edges = T
)
)
) %>%
add_title(
title = reactablefmtr::html("Kaggle's Community by Country <img src='https://www.svgrepo.com/show/387896/laptop.svg' alt='' width='40' height='40'>"),
margin = reactablefmtr::margin(t=0,r=0,b=3,l=0)
) %>%
add_subtitle("India is the most represented country, followed by the United States.", font_size = 14, font_weight = "normal") %>%
add_source("stesiam | Data : Kaggle Survey 2021", font_size = 12, align = "right")
aKaggle's Community by Country 
India is the most represented country, followed by the United States.
stesiam | Data : Kaggle Survey 2021
Women participation in DS
Generally, women are under-represented in labor market. According to the World Bank (2023), only one in two women participates in the labor market, in contrast to men whose corresponding participation is 7 in 10. Does DS community follow the same pattern? As it seems, it varies.
data$iso2c <- countrycode(data$Q3, "country.name", "iso2c")
data$iso2c = tolower(data$iso2c)theme_set(theme_light())
data %>%
ggplot() +
geom_col(aes(x = pct_women, y = reorder(Q3, pct_women), fill = pct_women)) +
scale_fill_gradient2(low="purple", high="purple4")+
geom_label(data = subset(data, pct_women == max(pct_women) | Q3 == "Greece" | pct_women == min(pct_women)), aes(x = pct_women - 1.5, y = reorder(Q3, pct_women), label = paste0(round(pct_women, digits = 1), "%")), family = "text", size = 2.3) +
ggflags::geom_flag(x = 0.3, aes(y = Q3,
country = iso2c),
size = 4) +
geom_vline(xintercept = mean(data$pct_women), linetype = "dashed", color = "pink1") +
geom_text(aes(x= mean(data$pct_women)+1, label=paste0("Average: ", round(mean(data$pct_women), digits = 2), " %"), y = "Colombia"), angle=270,
family = "text") +
scale_x_continuous(limits = c(0,50)) +
labs(
title = "<b>Women participation in DS community per country</b>",
subtitle = glue("Based on Kaggle's 2021 Survey women are underrepresented in DS. The country with the <br> highest women participation is Tunisia and Peru is one with the lowest. Last but not least,<br> **<span style= 'color: #001489;'>Greece</span>** has a relatively disappointing rate of women participation holding 15th place with <br> 15.7\\%, given the fact that the average is {round(mean(data$pct_women),digits = 2)} %"),
caption = "**Data:** Kaggle Survey 2021<br><b>stesiam</b>, 2023",
x = "Percentage (%) of Women",
y = "Countries"
) +
coord_cartesian(expand = FALSE)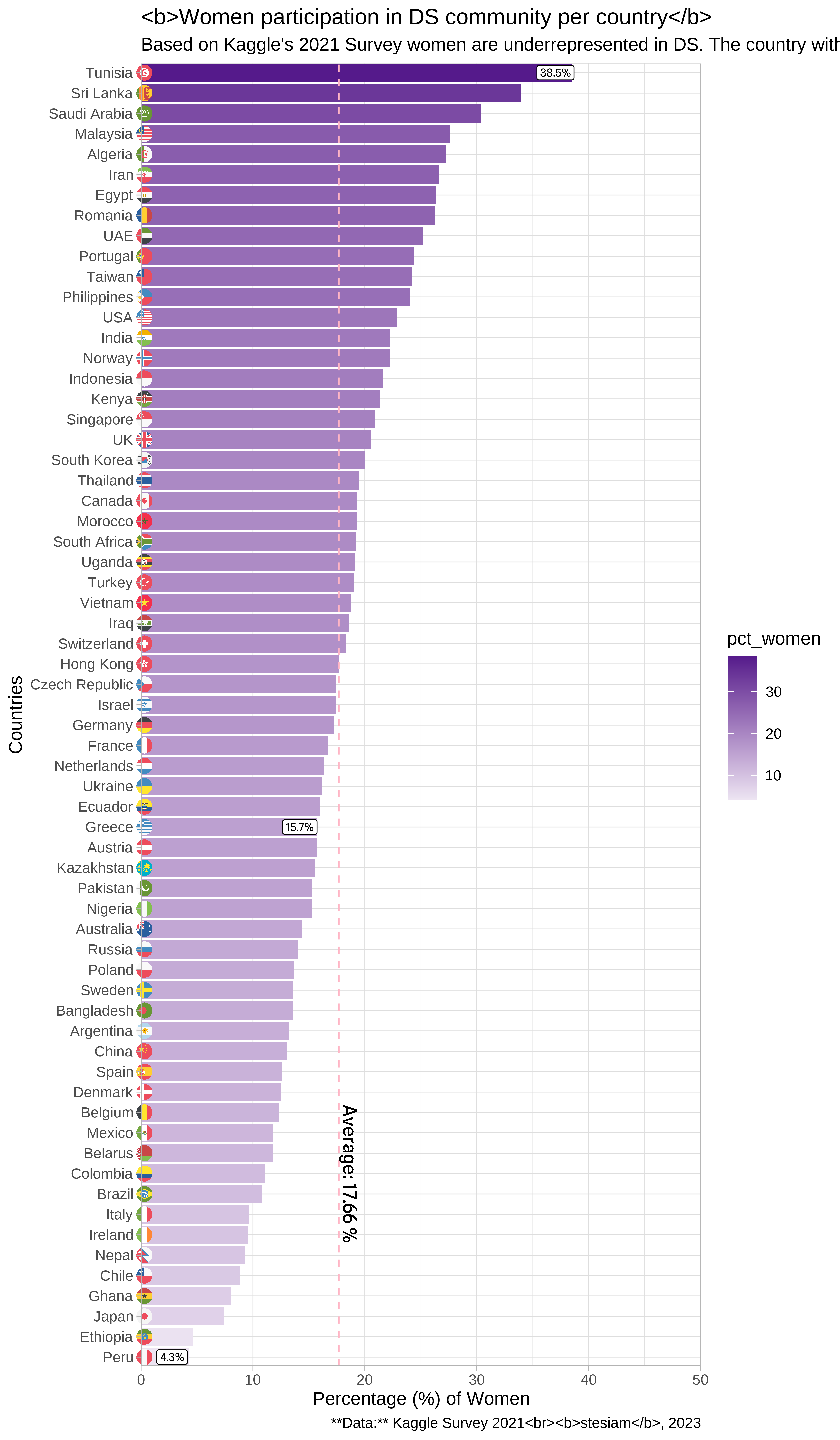
library(purrr)
data_decreasing = data %>% dplyr::arrange(-pct_women)
# Add emoji flags
data_decreasing <- data_decreasing %>%
mutate(flag = map_chr(iso2c, ~ {
chars <- utf8ToInt(toupper(.x))
paste0(
intToUtf8(127397 + chars[1]),
intToUtf8(127397 + chars[2])
)
}))
highchart() %>%
hc_chart(type = "bar", inverted = TRUE) %>%
hc_title(text = "<b>Women participation in DS community per country</b>") %>%
hc_subtitle(text = glue("Based on Kaggle's 2021 Survey women are underrepresented in DS. The country with the highest women participation is Tunisia and Peru is one with the lowest. Last but not least, <b>Greece</b> has a relatively disappointing rate of women participation holding 15th place with 15.7%, given the fact that the average is {round(mean(data$pct_women),digits = 2)} %") ) %>%
hc_caption(text="Data: Kaggle Survey 2021 | <b>stesiam</b>, 2023") %>% hc_xAxis(categories = data_decreasing$Q3, title = list(text = NULL)) %>%
hc_yAxis(title = list(text = "Percent (%)")) %>%
hc_legend(enabled = FALSE) %>%
hc_add_series(
name = "Women %",
data = map(seq_len(nrow(data_decreasing)), function(i) {
list(
y = data_decreasing$pct_women[i],
Women = data_decreasing$Women[i],
n = data_decreasing$n[i],
country = data_decreasing$Q3[i],
flag = data_decreasing$flag[i]
)
})
) %>%
hc_tooltip(
useHTML = TRUE,
formatter = JS("
function() {
var point = this.point;
return '<span style=\"font-size:22px\">' + point.flag + '</span> ' +
'<b>' + point.country + '</b><br>' +
'Percent: ' + Highcharts.numberFormat(this.y, 2) + '%<br>' +
'Women: ' + point.Women + ' / ' + point.n;
}
")
)Age Distribution
Greece’s Kaggle Community it is comprised from more elerly people comapred to the rest of Kaggle’s community. More specifically, Greece’s most prevalent age group is 25-29 and a sufficient proportion of users on their 40s. On the contrary, Kaggle’s community is quite youthy with most prevalent the three youngest age groups. Aggrevetating, those groups consist six out of ten userbase of Kaggle’s community.
`summarise()` has grouped output by 'Q3'. You can override using the `.groups`
argument.library(highcharter)
highchart() |>
hc_chart(type = "areaspline") |>
hc_title(text = "Age Distribution of Kaggle Community (🇬🇷 / 🌍)") |>
hc_xAxis(categories = unique(data1$Q1)) |>
hc_yAxis(title = list(text = "Population (%)")) |>
hc_tooltip(shared = TRUE, valueSuffix = " units") |>
hc_plotOptions(
areaspline = list(
fillOpacity = 0.5 # match the Highcharts demo's fill
)
) |>
hc_legend(
layout = "vertical",
align = "left",
verticalAlign = "top",
x = 450,
y = 100,
floating = TRUE,
borderWidth = 1
) |>
hc_add_series(
name = "Greece",
data = data1 %>% dplyr::filter(Q3 =="Greece") %>% pull(pct)
) |>
hc_add_series(
name = "Rest of the World",
data = data1 %>% dplyr::filter(Q3 =="Other") %>% pull(pct)
)Educational Background
`summarise()` has grouped output by 'Q3'. You can override using the `.groups`
argument.highchart() %>%
hc_chart(type = "bar") %>%
hc_title(text = "Age Distribution of Kaggle Community (🇬🇷 / 🌍)") %>%
hc_subtitle(text="Greek Kagglers have attained higher studies.") %>%
hc_caption(text="stesiam, 2023") %>%
hc_xAxis(categories = d$Q4,
title = list(text = NULL)) %>%
hc_yAxis(min = 0,
title = list(text = "Percentage (%) of total respondents by Country / Region", align = "high"),
labels = list(overflow = "justify")) %>%
hc_tooltip(valueSuffix = " units") %>%
hc_plotOptions(bar = list(dataLabels = list(enabled = TRUE))) %>%
hc_series(
list(name = "Greece", data = d %>% dplyr::filter(Q3 =="Greece") %>% pull(pct)),
list(name = "Rest World", data = d %>% dplyr::filter(Q3 =="Other") %>% pull(pct))
) %>%
hc_legend(
align = "center",
verticalAlign = "top",
layout = "horizontal"
)Programming Language
d1 = kaggle_2021_compare %>%
select(Q3, Q7_Part_1, Q7_Part_2) %>%
group_by(Q3) %>%
count(Q7_Part_1 == "Python") %>%
mutate(pct = round(n/sum(n)*100, digits = 1)) %>%
na.omit()
d2 = kaggle_2021_compare %>%
select(Q3, Q7_Part_2) %>%
group_by(Q3) %>%
count(Q7_Part_2 == "R") %>%
mutate(pct = round(n/sum(n)*100, digits = 1)) %>%
na.omit()
d3 = kaggle_2021_compare %>%
select(Q3, Q7_Part_8) %>%
group_by(Q3) %>%
count(Q7_Part_8 == "Julia") %>%
mutate(pct = round(n/sum(n)*100, digits = 1)) %>%
na.omit()Common Stacks
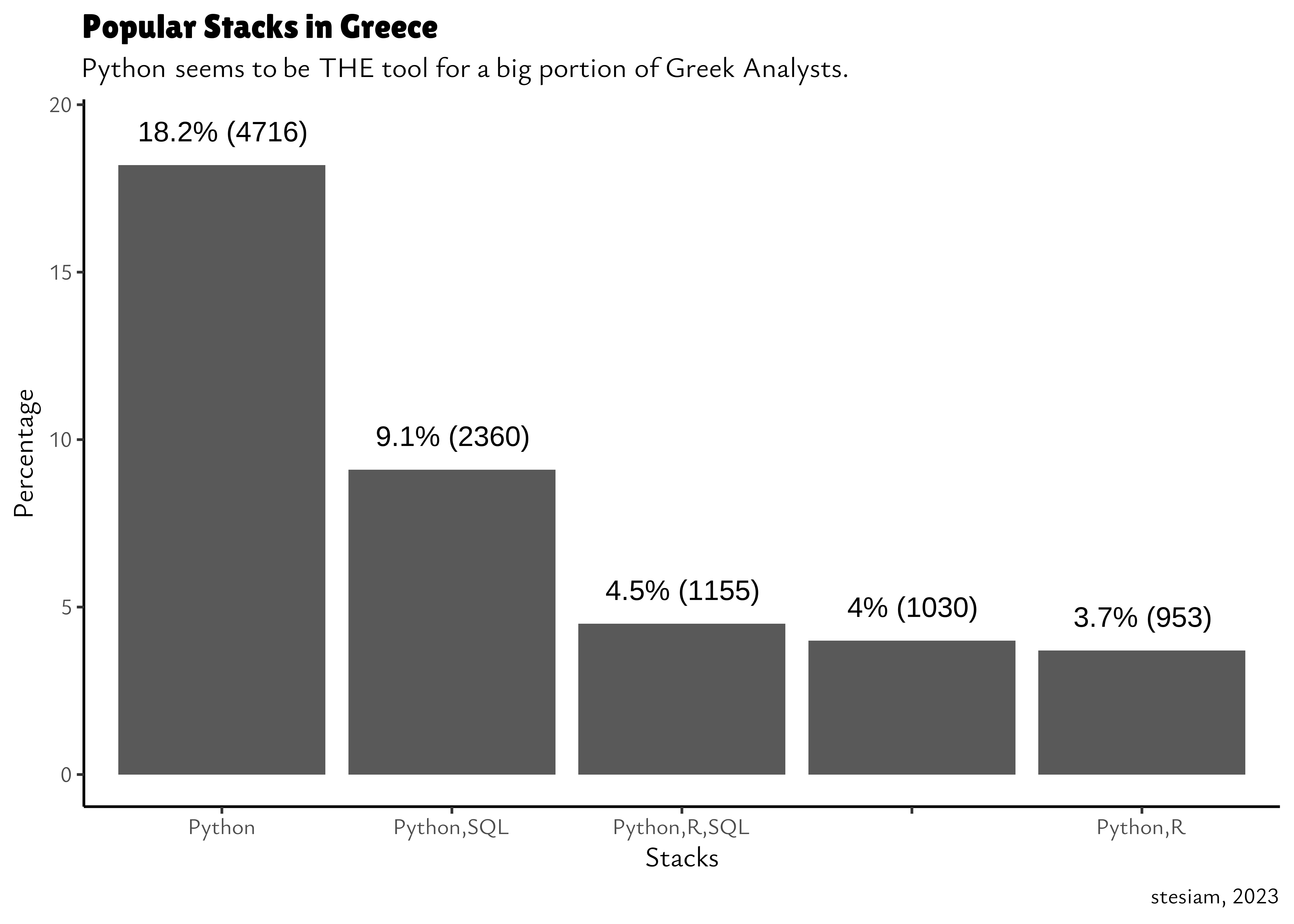
p1 = kaggle_2021_compare %>%
select(Q3, starts_with("Q7")) %>%
unite(Combined, starts_with("Q7"), sep = ",", na.rm = T) %>%
count(Q3, Combined) %>%
filter(Q3 == "Greece") %>%
mutate(pct = round(n/sum(n)*100, digits = 1)) %>%
arrange(-pct) %>%
filter(pct >=3) %>%
ggplot() +
geom_col(aes(x = reorder(Combined, -pct), y = pct)) +
geom_text(aes(x = Combined, y = pct+ 1, label = paste0(pct, "%", "", " (", n, ")"))) +
labs(
title = "Popular Stacks in Greece",
subtitle = "Python seems to be THE tool for a big portion of Greek Analysts.",
caption = "stesiam, 2023",
x = "Stacks",
y = "Percentage"
) +
theme_classic() +
theme(
plot.title = element_markdown(family = "title"),
plot.subtitle = element_markdown(family = "subtitle", lineheight = 0.4),
plot.caption = element_markdown(family = "subtitle"),
text = element_text(family = "subtitle")
)
kaggle_2021_compare %>%
select(Q3, starts_with("Q7")) %>%
unite(Combined, starts_with("Q7"), sep = ",", na.rm = T) %>%
count(Q3, Combined) %>%
filter(Q3 == "Other") %>%
mutate(pct = round(n/sum(n)*100, digits = 1)) %>%
arrange(-pct) %>%
filter(pct >=3) %>%
ggplot() +
geom_col(aes(x = reorder(Combined, -pct), y = pct)) +
geom_text(aes(x = Combined, y = pct+ 1, label = paste0(pct, "%", "", " (", n, ")"))) +
labs(
title = "Popular Stacks in Greece",
subtitle = "Python seems to be THE tool for a big portion of Greek Analysts.",
caption = "stesiam, 2023",
x = "Stacks",
y = "Percentage"
) +
theme_classic() +
theme(
plot.title = element_markdown(family = "title"),
plot.subtitle = element_markdown(family = "subtitle", lineheight = 0.4),
plot.caption = element_markdown(family = "subtitle"),
text = element_text(family = "subtitle")
)
p2 = kaggle_2021_compare %>%
select(Q3, starts_with("Q7")) %>%
unite(Combined, starts_with("Q7"), sep = ",", na.rm = T) %>%
count(Q3, Combined) %>%
filter(Q3 == "Other") %>%
mutate(pct = round(n/sum(n)*100, digits = 1)) %>%
arrange(-pct) %>%
filter(pct >=3) %>%
ggplot() +
geom_col(aes(x = reorder(Combined, -pct), y = pct)) +
geom_text(aes(x = Combined, y = pct+ 1, label = paste0(pct, "%", "", " (", n, ")"))) +
labs(
title = "Popular Stacks in Greece",
subtitle = "Python seems to be THE tool for a big portion of Greek Analysts.",
caption = "stesiam, 2023",
x = "Stacks",
y = "Percentage"
) +
theme_classic() +
theme(
plot.title = element_markdown(family = "title"),
plot.subtitle = element_markdown(family = "subtitle", lineheight = 0.4),
plot.caption = element_markdown(family = "subtitle"),
text = element_text(family = "subtitle")
)IDEs
Python users
R users
Jobs
jobs1 = kaggle_2021_compare %>%
select(Q3, Q5) %>%
filter(Q3 == "Greece") %>%
count(Q5) %>%
arrange(-n) %>%
head(8) %>%
mutate(pct = round(n/sum(n)*100, 1))
jobs2 = kaggle_2021_compare %>%
select(Q3, Q5) %>%
filter(Q3 == "Other") %>%
count(Q5) %>%
arrange(-n) %>%
head() %>%
mutate(pct = round(n/sum(n)*100, 1))Conclusions
Acknowledgements
Dataset based on 2021 Kaggle Machine Learning & Data Science Survey
Image by Christina Smith from Pixabay
References
Arel-Bundock, V. (2025). Countrycode: Convert country names and country codes. Retrieved from https://vincentarelbundock.github.io/countrycode/
Arel-Bundock, V., Enevoldsen, N., & Yetman, C. (2018). Countrycode: An r package to convert country names and country codes. Journal of Open Source Software, 3(28), 848. Retrieved from https://doi.org/10.21105/joss.00848
Auguie, B. (2017). gridExtra: Miscellaneous functions for "grid" graphics. https://doi.org/10.32614/CRAN.package.gridExtra
Auguie, B., Goldie, J., & Thériault, R. (2023). Ggflags: Plot flags of the world in ggplot2. Retrieved from https://github.com/jimjam-slam/ggflags
Cuilla, K. (2022). Reactablefmtr: Streamlined table styling and formatting for reactable. Retrieved from https://kcuilla.github.io/reactablefmtr/
Heads or Tails. (2020). Kaggle has 10 million registered users! Retrieved from https://www.kaggle.com/discussions/general/332147
Hester, J., & Bryan, J. (2024). Glue: Interpreted string literals. Retrieved from https://glue.tidyverse.org/
Iannone, R. (2024). Fontawesome: Easily work with font awesome icons. Retrieved from https://github.com/rstudio/fontawesome
Kunst, J. (2022). Highcharter: A wrapper for the highcharts library. Retrieved from https://jkunst.com/highcharter/
Lin, G. (2025). Reactable: Interactive data tables for r. Retrieved from https://glin.github.io/reactable/
O’Hara-Wild, M. (2018, July 10). Arranging Hex Stickers in R. Retrieved from https://mitchelloharawild.github.io/mitchelloharawild.com//blog/hexwall
Qiu, Y., & See file AUTHORS for details., authors/contributors of the included fonts. (2020). Showtextdb: Font files for the showtext package. https://doi.org/10.32614/CRAN.package.showtextdb
Qiu, Y., & See file AUTHORS for details., authors/contributors of the included fonts. (2024a). Sysfonts: Loading fonts into r. Retrieved from https://github.com/yixuan/sysfonts
Qiu, Y., & See file AUTHORS for details., authors/contributors of the included software. (2024b). Showtext: Using fonts more easily in r graphs. Retrieved from https://github.com/yixuan/showtext
R Core Team. (2025). R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing. Retrieved from https://www.R-project.org/
The World Bank. (2023). Labor force participation rate (. Retrieved from https://genderdata.worldbank.org/indicators/sl-tlf-acti-zs/?geos=WLD&view=trend
Wickham, H. (2016). ggplot2: Elegant graphics for data analysis. Springer-Verlag New York. Retrieved from https://ggplot2.tidyverse.org
Wickham, H. (2025). Forcats: Tools for working with categorical variables (factors). Retrieved from https://forcats.tidyverse.org/
Wickham, H., Chang, W., Henry, L., Pedersen, T. L., Takahashi, K., Wilke, C., … van den Brand, T. (2025). ggplot2: Create elegant data visualisations using the grammar of graphics. Retrieved from https://ggplot2.tidyverse.org
Wickham, H., François, R., Henry, L., Müller, K., & Vaughan, D. (2023). Dplyr: A grammar of data manipulation. Retrieved from https://dplyr.tidyverse.org
Wickham, H., Hester, J., & Bryan, J. (2025). Readr: Read rectangular text data. Retrieved from https://readr.tidyverse.org
Wickham, H., Vaughan, D., & Girlich, M. (2025). Tidyr: Tidy messy data. Retrieved from https://tidyr.tidyverse.org
Wilke, C. O., & Wiernik, B. M. (2022). Ggtext: Improved text rendering support for ggplot2. Retrieved from https://wilkelab.org/ggtext/
Zhu, H. (2024). kableExtra: Construct complex table with kable and pipe syntax. Retrieved from http://haozhu233.github.io/kableExtra/
Citation
BibTeX citation:
@online{2023,
author = {, stesiam},
title = {Kaggle’s {Greek} {Community}},
date = {2023-05-06},
url = {https://stesiam.com/posts/kaggle-greek-community/},
langid = {en}
}
For attribution, please cite this work as:
stesiam. (2023, May 6). Kaggle’s Greek Community. Retrieved from https://stesiam.com/posts/kaggle-greek-community/