Bray, A., Ismay, C., Chasnovski, E., Couch, S., Baumer, B., & Cetinkaya-Rundel, M. (2022).
Infer: Tidy statistical inference. Retrieved from
https://github.com/tidymodels/infer
Couch, S. P., Bray, A. P., Ismay, C., Chasnovski, E., Baumer, B. S., & Çetinkaya-Rundel, M. (2021).
infer: An
R package for tidyverse-friendly statistical inference.
Journal of Open Source Software,
6(65), 3661.
https://doi.org/10.21105/joss.03661
Dua, D., & Graff, C. (2017).
UCI machine learning repository. University of California, Irvine, School of Information; Computer Sciences. Retrieved from
http://archive.ics.uci.edu/ml
Falbel, D., Damiani, A., Hogervorst, R. M., Kuhn, M., & Couch, S. (2022).
Bonsai: Model wrappers for tree-based models. Retrieved from
https://bonsai.tidymodels.org/
Hvitfeldt, E. (2022).
Themis: Extra recipes steps for dealing with unbalanced data. Retrieved from
https://github.com/tidymodels/themis
Iannone, R. (2023).
Fontawesome: Easily work with font awesome icons. Retrieved from
https://github.com/rstudio/fontawesome
Kabacoff, R. (2019). Data visualization with r. URL Https://Rkabacoff. Github. Io/Datavis.
Kirenz, J. (2021). Classification with tidymodels, workflows and recipes. Retrieved November 22, 2022, from
https://www.kirenz.com/post/2021-02-17-r-classification-tidymodels/#data-preparation
Kuhn, M. (2022a).
Modeldata: Data sets useful for modeling examples. Retrieved from
https://modeldata.tidymodels.org
Kuhn, M. (2022b).
Tune: Tidy tuning tools. Retrieved from
https://tune.tidymodels.org/
Kuhn, M., & Couch, S. (2022).
Workflowsets: Create a collection of tidymodels workflows. Retrieved from
https://github.com/tidymodels/workflowsets
Kuhn, M., & Frick, H. (2022).
Dials: Tools for creating tuning parameter values. Retrieved from
https://dials.tidymodels.org
Kuhn, M., & Vaughan, D. (2022).
Parsnip: A common API to modeling and analysis functions. Retrieved from
https://github.com/tidymodels/parsnip
Kuhn, M., Vaughan, D., & Hvitfeldt, E. (2022).
Yardstick: Tidy characterizations of model performance. Retrieved from
https://github.com/tidymodels/yardstick
Kuhn, M., & Wickham, H. (2020).
Tidymodels: A collection of packages for modeling and machine learning using tidyverse principles. Retrieved from
https://www.tidymodels.org
Kuhn, M., & Wickham, H. (2022a).
Recipes: Preprocessing and feature engineering steps for modeling. Retrieved from
https://github.com/tidymodels/recipes
Kuhn, M., & Wickham, H. (2022b).
Tidymodels: Easily install and load the tidymodels packages. Retrieved from
https://tidymodels.tidymodels.org
Moro, S., Cortez, P., & Rita, P. (2014). A data-driven approach to predict the success of bank telemarketing. Decision Support Systems, 62, 22–31.
Müller, K., & Wickham, H. (2023).
Tibble: Simple data frames. Retrieved from
https://tibble.tidyverse.org/
R Core Team. (2021).
R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing. Retrieved from
https://www.R-project.org/
R-Bloggers. (2017). 5 ways to measure running time of r code. Retrieved November 20, 2022, from
https://www.r-bloggers.com/2017/05/5-ways-to-measure-running-time-of-r-code/
R-Bloggers. (2020). How to use lightgbm with tidymodels. Retrieved November 20, 2022, from
https://www.r-bloggers.com/2020/08/how-to-use-lightgbm-with-tidymodels/
Robinson, D., Hayes, A., & Couch, S. (2022).
Broom: Convert statistical objects into tidy tibbles. Retrieved from
https://broom.tidymodels.org/
Silge, J., Chow, F., Kuhn, M., & Wickham, H. (2022).
Rsample: General resampling infrastructure. Retrieved from
https://rsample.tidymodels.org
Vaughan, D., & Couch, S. (2022).
Workflows: Modeling workflows. Retrieved from
https://github.com/tidymodels/workflows
Wickham, H. (2016).
ggplot2: Elegant graphics for data analysis. Springer-Verlag New York. Retrieved from
https://ggplot2.tidyverse.org
Wickham, H. (2022).
Forcats: Tools for working with categorical variables (factors). Retrieved from
https://forcats.tidyverse.org/
Wickham, H., Chang, W., Henry, L., Pedersen, T. L., Takahashi, K., Wilke, C., … van den Brand, T. (2024).
ggplot2: Create elegant data visualisations using the grammar of graphics. Retrieved from
https://ggplot2.tidyverse.org
Wickham, H., François, R., Henry, L., Müller, K., & Vaughan, D. (2023).
Dplyr: A grammar of data manipulation. Retrieved from
https://dplyr.tidyverse.org
Wickham, H., & Girlich, M. (2022).
Tidyr: Tidy messy data. Retrieved from
https://tidyr.tidyverse.org
Wickham, H., & Henry, L. (2023).
Purrr: Functional programming tools. Retrieved from
https://purrr.tidyverse.org/
Wickham, H., Hester, J., & Bryan, J. (2022).
Readr: Read rectangular text data. Retrieved from
https://readr.tidyverse.org
Wickham, H., Pedersen, T. L., & Seidel, D. (2023).
Scales: Scale functions for visualization. Retrieved from
https://scales.r-lib.org
Wilke, C. O., & Wiernik, B. M. (2022).
Ggtext: Improved text rendering support for ggplot2. Retrieved from
https://wilkelab.org/ggtext/
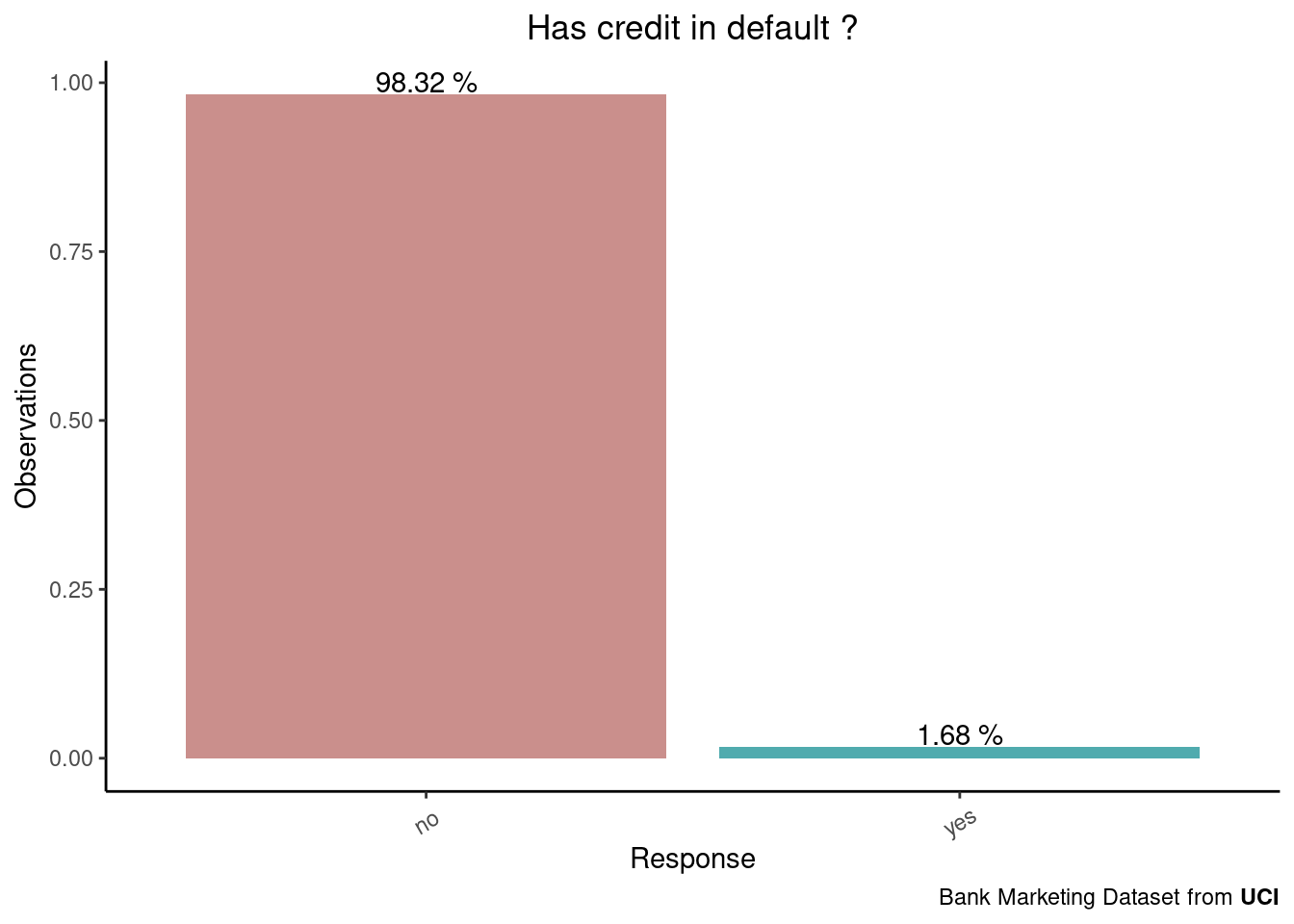
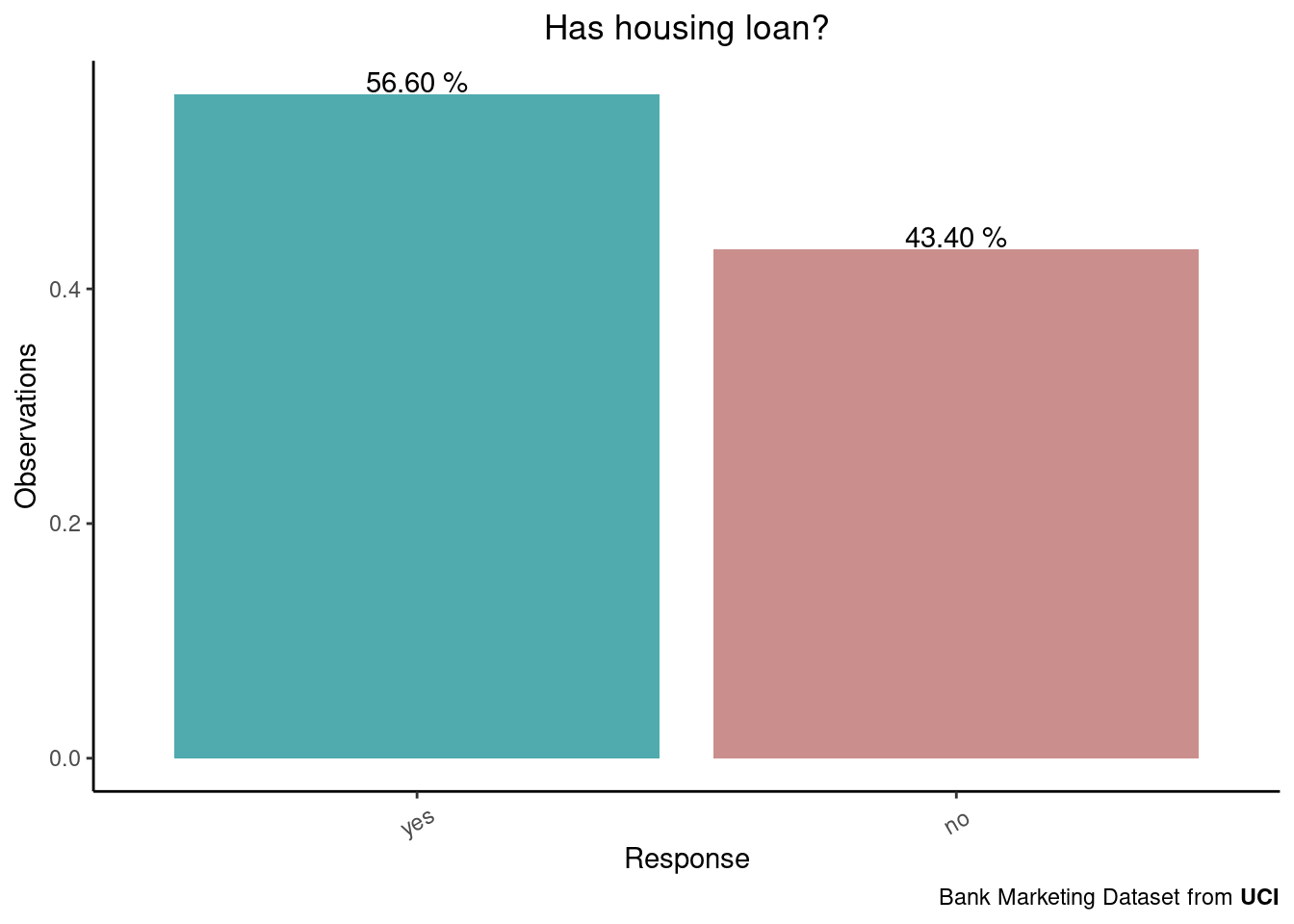
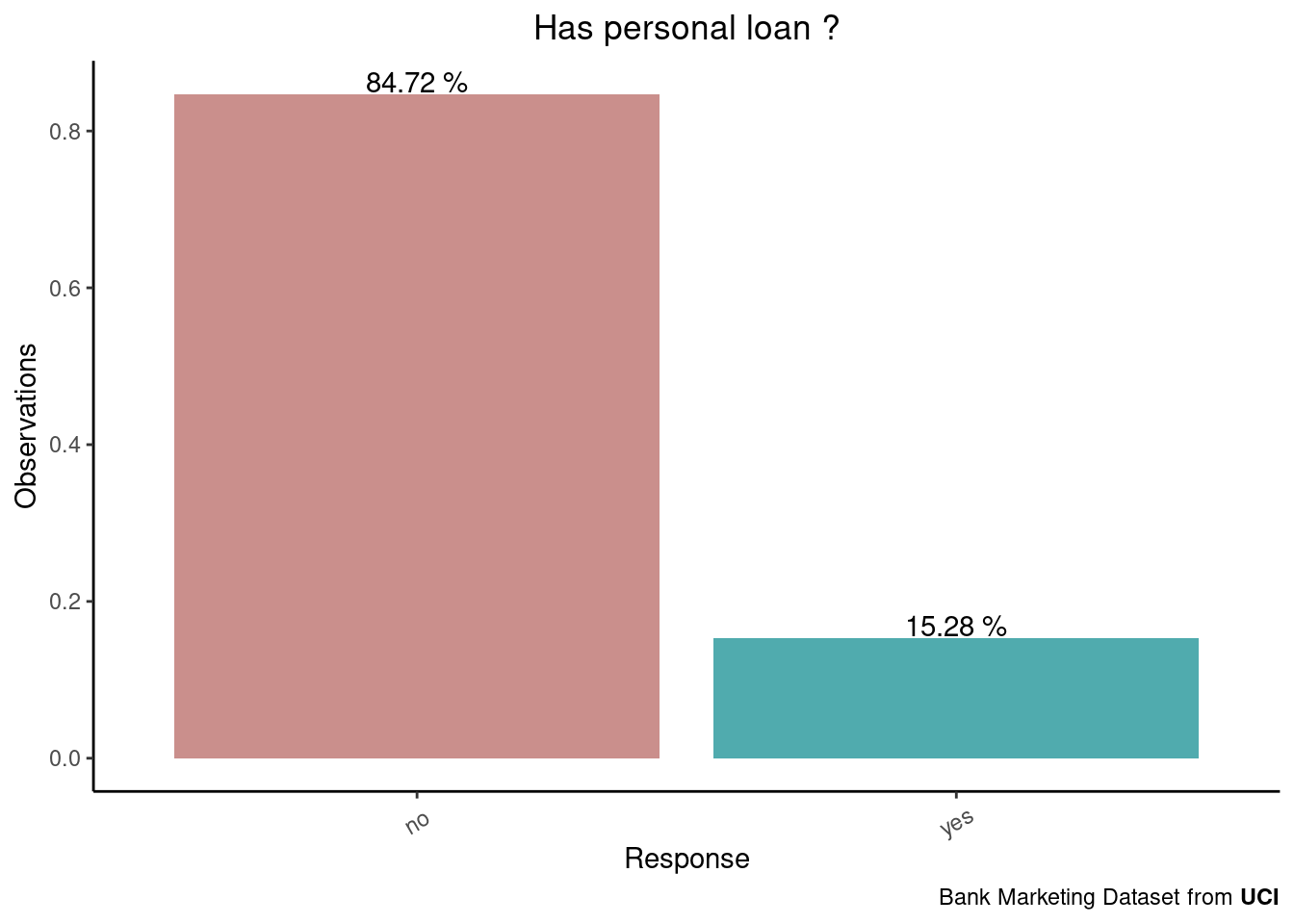
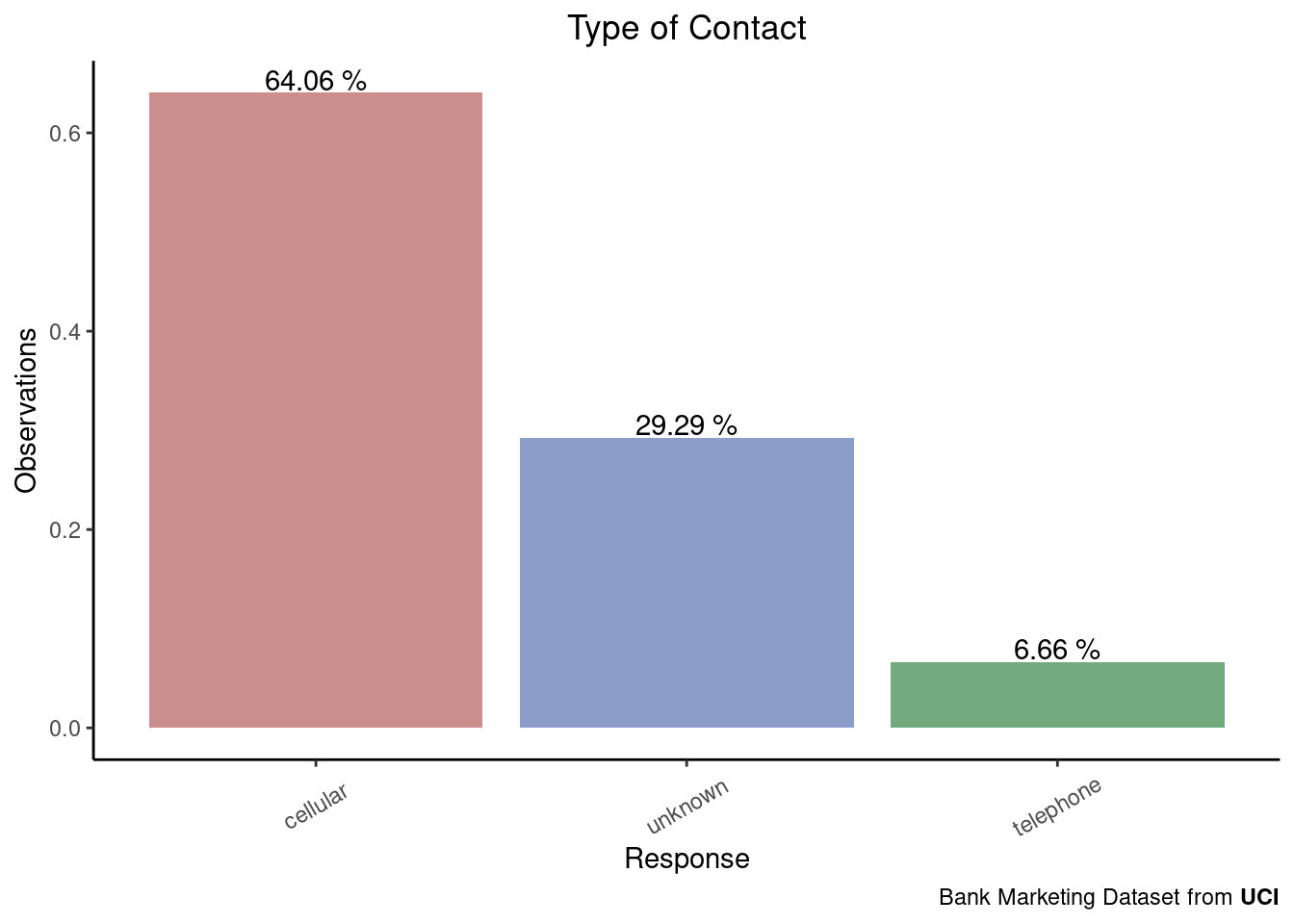
)-1.png)